Reactive streams
Source code for this article can be found on Github.
In this article we shall take a look at reactive streams. First we’ll discover how reactive streams work, what problems they solve and how this fits into our asynchronous journey. We’ll finish this article by rewriting our weather example to use reactive streams.
Reactive streams
Reactive streams are an embodiment of the publish-subscribe pattern, which passes data in a type safe manner to build pipelines in which data can be send over an asynchronous boundary. This definition is a bit abstract, so we’ll look at these streams piece by piece.
Origin
The idea of reactive streams originates from somewhere in 2013 and was pioneered by Netflix, Pivotal and Lightbend1. This group of companies created an open format which reactive stream libraries can implement in order to stay interoperable with each other. The original specification consists of a lightweight jar with 4 interfaces. This interface specification is now part of Java 9 as the Flow class.
Implementations of the reactive streams specification includes Netflix’s RXJava (as part of the ReactiveX project), Pivotals Project Reactor and Lightbends Akka Streams. These libraries each provide their own publishers, operators and subscribers. Besides the reactive streams libraries themselves, some new versions of technologies added libraries that support working with publishers and subscribers, most notably is Spring 5 which enables web programming using reactive streams2.
So what are these streams?
The reactive streams specification exists of four elements:
- Publisher: a publisher is an entity that will emit objects.
- Operator: an operator is created by a publisher and it will return a new publisher. It can perform operation such as transforming objects, delaying emitted objects, filtering object, etc. Because operators always return a publisher, operators can be chained. Beware that this is not the builder pattern: as the order of operators matters.
- Subscriber: A subscriber handles messages been sent by a publisher.
- Subscription: An object holding the subscription itself.
Let’s try a quick example to get a feel for reactive streams, in our example we’ll use Project Reactor. We can start using Project Reactor by importing the reactor-core Maven dependency.
// 1
Flux<String> publisher = Flux.just("one", "two", "three");
// 2
Flux<String> upper = publisher.map(String::toUpperCase);
// 3
upper.subscribe(System.out::println);
- We create a
Publisher. OurPublisheris of typeFlux<T>which is one of thePublishertypes provided by Project Reactor. A number of simple factory functions are provided, likejust()which creates aFlux<T>which emits its parameters as values. map()is an operator function which means it returnsFlux<T>of it’s own. Themap()function takes all objects coming from ourPublisherand transforms it using a lambda, in our case applying thetoUpperCase()function to eachString.- One of the advantages of reactive streams is that (most of them3) won’t perform any logic until subscribed to.
If we leave out our
subscribe()function, our program wouldn’t do anything at all. Here we subscribe and callSystem.out.println()for eachStringobject received.
Running this example results in the following output:
ONE
TWO
THREE
A key feature of reactive streams is that we don’t care about latency of messages.
We program the actions that should be performed on data coming in and don’t care if our functions are performed
synchronously or asynchronously. The map() function we wrote would be performed in a blocking way in our example,
but if we rewrite our code to include a delay()
(an operator that, as a side effect, defines that actions after that should be processed asynchronously)
it’s subscriber will finish asynchronously (that is: in another thread).
This concept of asynchronous abstraction can become complex to wrap our heads around so let’s practice by doing this by example:
String blockingResult = "";
String nonBlockingResult = "";
// blocking
Flux.just("one", "two", "three")
.map(String::toUpperCase)
.subscribe(val -> blockingResult += val + " + ");
System.out.println("blocking: " + blockingResult);
Flux.just("four", "five", "six")
.delayElements(Duration.ofMillis(500))
.map(String::toUpperCase)
.subscribe(val -> {
nonBlockingResult += val + " + ";
System.out.println("updated non-blocking: " + val);
});
System.out.println("non-blocking: " + nonBlockingResult);
This will print the following output:
blocking: ONE + TWO + THREE +
non-blocking:
updated non-blocking: FOUR
updated non-blocking: FIVE
updated non-blocking: SIX
So what happens in this example? Reactive streams operators don’t automatically switch to other threads.
The truth is that communicating and managing threads causes some overhead,
so some calls are actually faster in a synchronous context.
Our map() operator alone doesn’t start the subscriber in a new thread and we thus see that the result
of the blocking operator as the first log entry.
In contrary, our stream containing the delayElements() function will publish its data in a new thread,
thus our main thread does not block when creating and subscribing to that Flux<T>.
This means that our second log entry doesn’t include any results and print an empty result.
Q. But isn’t there a the possibility the first statement also ran asynchronously and it simply returned all values fast enough to be included in our log call?
A. You can check this by cloning the code on Github and adding:
System.out.println(Thread.currentThread());in both subscribe callbacks and you’ll see that this isn’t the case.
Operators
The Reactive libraries come with operators that handle common operations that might take multiple lines of code normally.
Some operators are the same as
Java 8’s streaming API,
which is not surprising because lists of items can sometimes be handled the same way as items streamed asynchronously.
Other operators are specific to the Streaming semantics,
such as onBackpressureBuffer.
Operators always return a new Publisher object which makes it possible to chain operations.
Transformations made by operators are best described in marble diagrams:
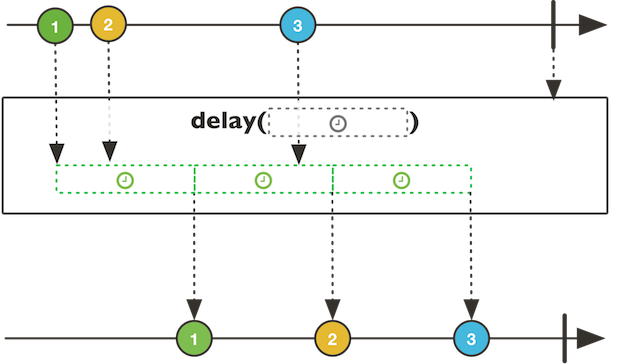
Marble diagrams show publishers as arrows. The line shows time from left to right. The perpendicular line shows when a publisher is complete. Each marble shows an emitted message. In the middle we see the function, including provided parameters. At the bottom of the diagram we see the resulting publisher outputted by the operator function.
These marble diagrams are actually so helpful that they are provided for most operator in the JavaDoc of Reactor.
Using operators
Let’s look at an example where the use of operators shine:
Imagine us wanting to parse Markdown input to HTML in real time. We want to render our input in a different thread so we don’t block the user from typing. Also parsing on each key press would be wasteful, so instead we parse only when the user didn’t type anything for some time.
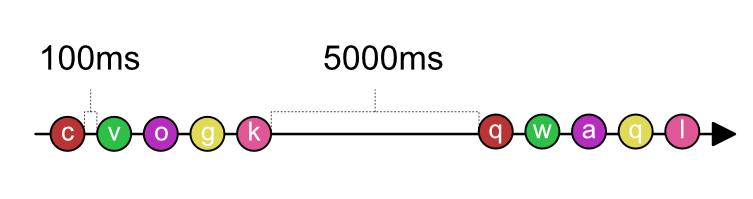
In our example fakeInput will be a reactive stream emitting 5 random char objects,
each 100 ms apart and then waiting 3 seconds until we send the next chars. Let’s see this in a marble diagram.
Our goal is to not store the value somewhere but to combine them in the objects the stream returns,
kind of like a reduce function. Then we only want to subscribe to our total value when no object came through for 200 ms,
let’s look at our implementation:
fakeInput
.scan("", (acc, val) -> acc += val)
.sampleTimeout(c -> Mono.delay(Duration.ofMillis(200)))
.subscribe(System.out::println);
Our scan operation will work like this:
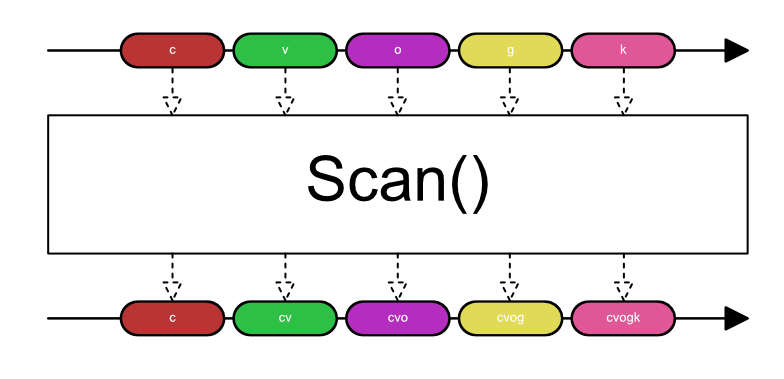
scan() works just like reduce(), but instead of returning one value it returns the accumulated value each time
a message comes in.
Now let’s take a look at sampleTimeout():
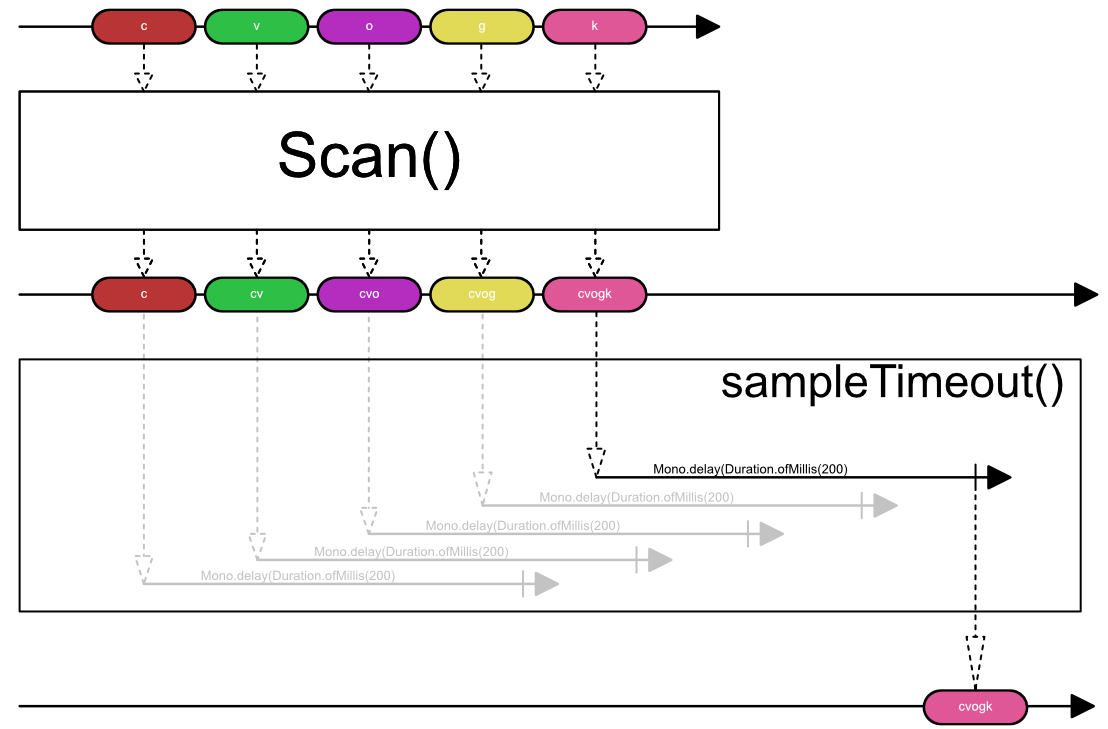
Each time a new message comes in, it starts a new publisher (Mono<T>) which completes in 200 ms.
When all Mono<T> objects complete it send only its last message to it’s new publisher.
The only thing we have to do now is subscribe to this new stream and we have the functionality we wanted.
The actual publisher we subscribe to will look like this:
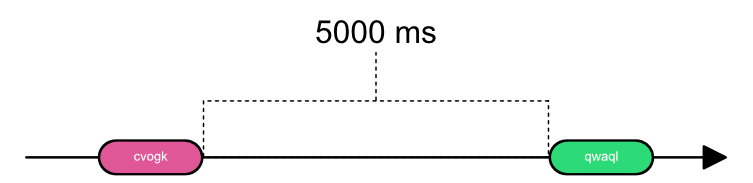
These 2 messages are exactly what we wanted to subscribe to. This took just 4 lines of code to achieve thanks to the operators provided by Project Reactor. To appreciate the true power of operators you really have to get your hands dirty with them. In fact, the stream that provided our input data for this example was created using just a few operators:
Flux<Character> fakeInput = Flux.interval(Duration.ofMillis(5000))
.flatMap(i -> Flux.range(1, 5).delayElements(Duration.ofMillis(100)))
.map(i -> getRandomChar());
To understand this code, just try to decipher it using the API page as an exercise.
Back pressure
Back pressure is something that was recently added as part of the reactive streams specification. Back pressure means that subscribers only relieve publishers of messages once the subscribers are ready to receive new messages.
Without back pressure message 4 will be put on top of the subscriber buffer. If the subscribers handles messages quicker than the publisher publishes them, the buffer will remain small.
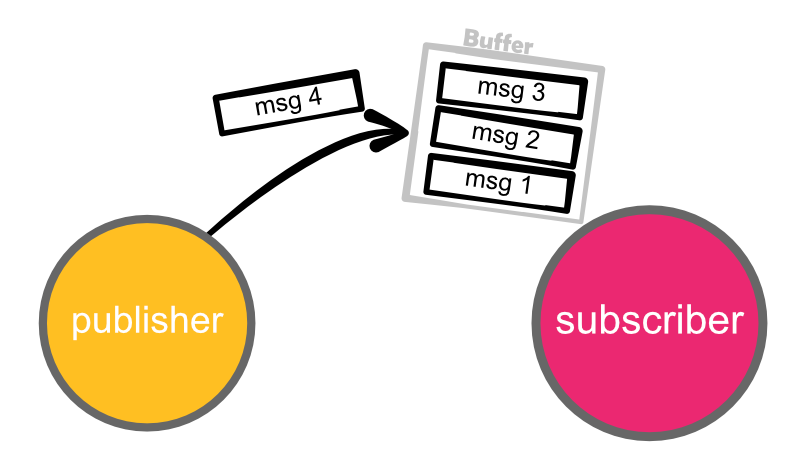
Problems arise when the publisher pushes messages quicker than the subscriber can handle. Messages will pile up in the buffer till eventually the system runs out of memory and crashes.
This method is called a push mechanism because the publisher pushes the messages to the subscriber.
When using back pressure, the buffer is maintained at the publisher. A subscriber will request a message from the publisher whenever it’s done processing its messages.
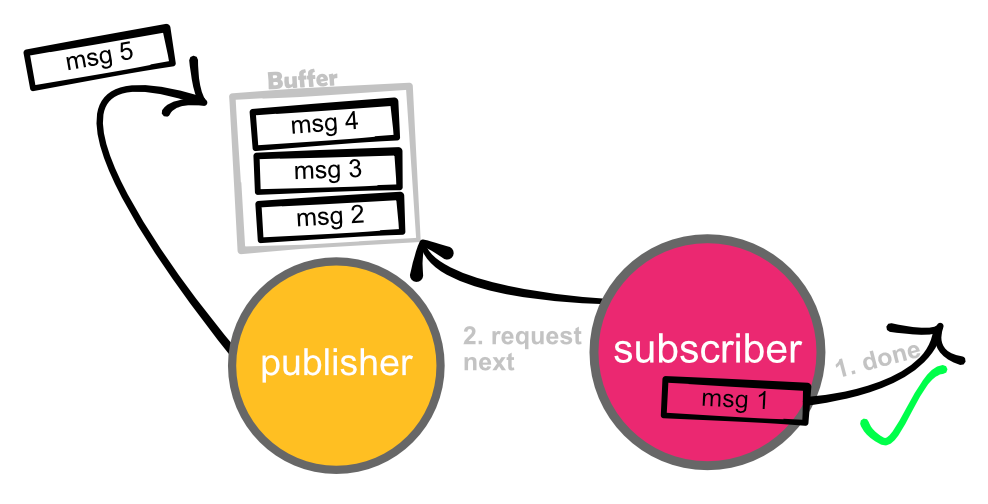
Q. So why is this better?
A. Because the publisher produces the messages, it should implement what to do when something goes wrong. Compare this with an employee (subscriber) of a supermarket that has to stock more shelves than he can manage. The manager (publisher) should fix this problem by hiring new employees or accepting emptier shelves, not the employee.
One use case in a microservice architecture is that we can use back pressure to optimize our messaging service. By implementing one of the new reactive libraries we can signal back to the message service if new messages could be processed. Imagine two microservices that can handle the same tasks. Service A starts with a message that takes 1 hour to process whilst Service B starts with a message that takes just 10 minutes. When using round-robin dispatching at the message service, the third message would be handed to service A sitting idle in its mailbox for an hour, whilst it could be processed after 10 minutes at service B.
By using back pressure our message service connector could request the message when it’s done processing its last message, thus the third message would be send to Service B.
Back pressure is called using a pull based mechanism. Pull based mechanisms have the disadvantage of not allowing publishers to work at full speed when the subscribers can handle the total workload. The reactive specification has an answer to this drawback: subscribers can request more messages, thus buffering a bounded amount of messages themselves. If a subscriber requests more messages than the publisher has available, the publisher switches to a push mechanism for at least the amount of messages that are requested by the publisher.
Weather example
Let’s rewrite the asynchronous part of our weather application using these streams.
We start by writing our WeatherService that provides a fake, blocking, method.
class WeatherService {
private long latency = 4000;
private double maxTemp = 30;
Mono<WeatherReport> getTemperature(String type, String location) { // <- 2
return Mono.defer(() -> // <- 3
Mono.just(new WeatherReport(type, fetchWeather(type, location))))
.subscribeOn(Schedulers.parallel()); // <- 4
}
private Double fetchWeather(String type, String location) { // <- 1
double temperature = Math.random() * maxTemp;
try {
Thread.sleep(latency);
} catch (InterruptedException e) {
e.printStackTrace();
}
return temperature;
}
}
We also store a result in a WeatherReport object:
class WeatherReport {
public String type;
public Double temperature;
WeatherReport(String type, Double temperature) {
this.type = type;
this.temperature = temperature;
}
}
Now in our main app we’ll write the code to handle getting both blocking calls asynchronously.
LocalTime start = LocalTime.now();
WeatherService weatherService = new WeatherService();
String location = "Eindhoven";
Flux.just("actual", "predicted")
.flatMap(type -> weatherService.getTemperature(type, location)) // <- 5
.scan(new HashMap<String, Double>(), (acc, val) -> { // <- 6
acc.put(val.type, val.temperature);
return acc;
})
.filter(result -> result.size() > 1) // <- 7
.subscribe(result -> {
LocalTime end = LocalTime.now();
System.out.println(result + " finished in "
+ Duration.between(start, end).toMillis()
+ "ms");
});
When run, this provides the following output:
{actual=13.678773126624673, predicted=16.631860503562045} finished in 4216ms
Each request we made took 4 seconds, so this code actually ran asynchronously. Now let’s examine what we just wrote:
- Our
fetchWeather()function doesn’t have any reactive parts, it’s a straight old blocking Java function call. - We want to wrap our
fetchWeather()function with something reactive, this means returning aMono<T>(non-blocking) which promises to return aWeatherReportsomewhere in the future. defer()is a trick. It takes a lambda which runs the blocking code. If we didn’t use this trick, Java would execute our blocking code first without touching any reactive streams related functions, thus making it impossible for thegetTemperature()to return non blocking.subscribeOn()will make sure that this stream is started on a new thread.- The
flatMap()operator works primarily as amap()function, it takes our “actual” and “predicted” values and maps them to reports. The difference with a normal map is thatflatMap()may take reactive objects as a return type which emitted messages it “flattens” onto a single stream. - We saw the
scan()function earlier in this article. It start initially with an emptyHashMap<T>. Each message is thenput()in theHashMapafter which the result is sent downstream. - We only want to emit the message when the full result is ready.
filter()only forwards a message downstream once it meets its requirements.
Finally, let’s visualize our data being transformed through our stream:
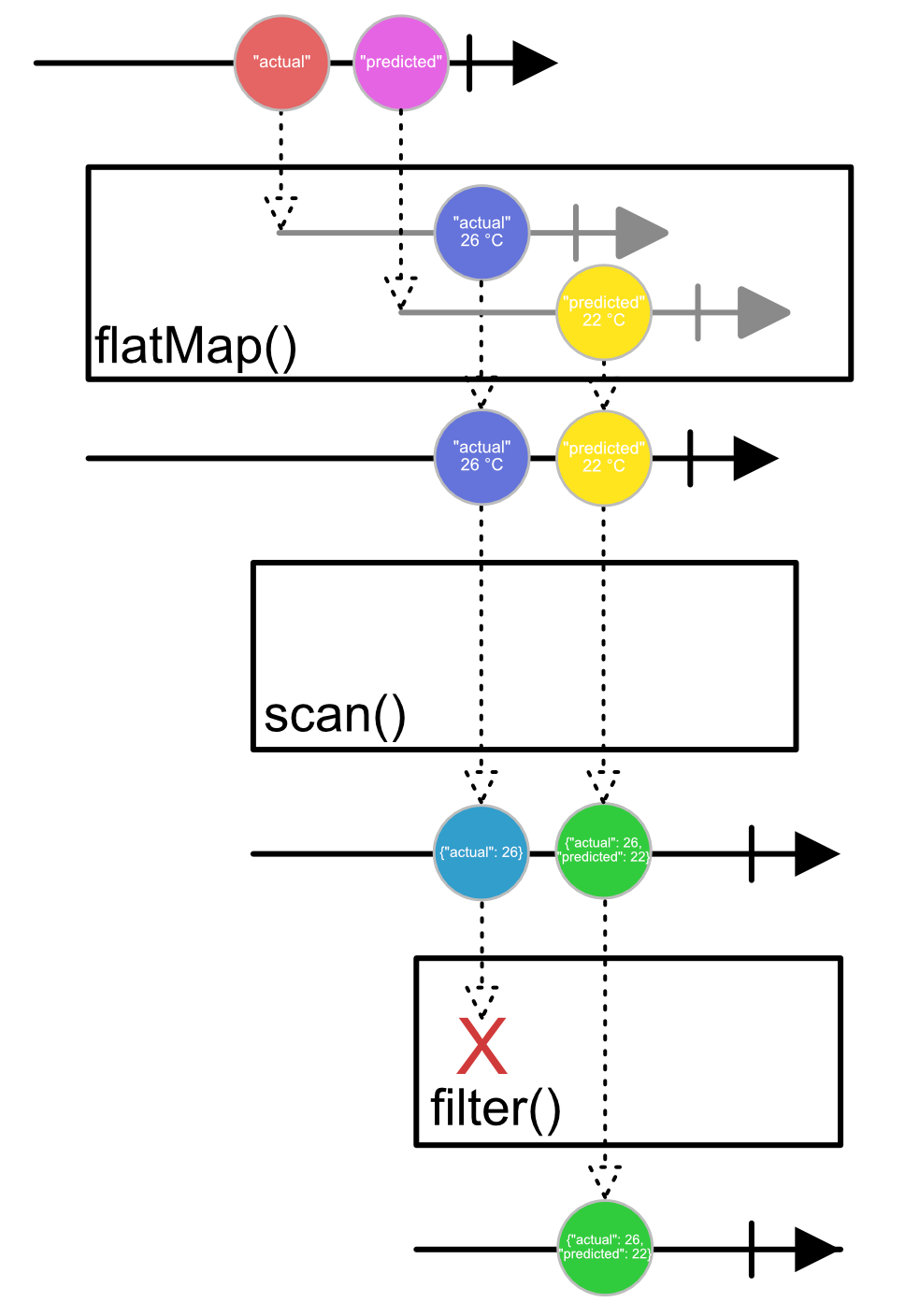
Conclusion
Using reactive streams allows us to write code that handles concurrency problems with elegance.
We can be sure that streams that we write can consume and publish data to other libraries by implementing Java 9s new Flow class.
Finally, by ensuring back pressure is communicated throughout the stream, we ensure buffer problems are handled at the right level.
-
Lightbend is the developer of the Akka streams we saw in an earlier article ↩
-
Via Spring Webflux. ↩
-
There are publishers that start emitting when created, but we’ll not focus on these in this article. ↩
About the author

My name is Thomas Kleinendorst. I'm currently doing my internship at Bottomline where I'm investigating Reactive technologies and how they fit in their new architecture.